- 10.6. 求近义词和类比词
- 10.6.1. 使用预训练的词向量
- 10.6.2. 应用预训练词向量
- 10.6.2.1. 求近义词
- 10.6.2.2. 求类比词
- 10.6.3. 小结
- 10.6.4. 练习
- 10.6.5. 参考文献
10.6. 求近义词和类比词
在“word2vec的实现”一节中,我们在小规模数据集上训练了一个word2vec词嵌入模型,并通过词向量的余弦相似度搜索近义词。实际中,在大规模语料上预训练的词向量常常可以应用到下游自然语言处理任务中。本节将演示如何用这些预训练的词向量来求近义词和类比词。我们还将在后面两节中继续应用预训练的词向量。
10.6.1. 使用预训练的词向量
MXNet的contrib.text包提供了跟自然语言处理相关的函数和类(更多参见GluonNLP工具包[1])。下面查看它目前提供的预训练词嵌入的名称。
- In [1]:
- from mxnet import nd
- from mxnet.contrib import text
- text.embedding.get_pretrained_file_names().keys()
- Out[1]:
- dict_keys(['glove', 'fasttext'])
给定词嵌入名称,可以查看该词嵌入提供了哪些预训练的模型。每个模型的词向量维度可能不同,或是在不同数据集上预训练得到的。
- In [2]:
- print(text.embedding.get_pretrained_file_names('glove'))
- ['glove.42B.300d.txt', 'glove.6B.50d.txt', 'glove.6B.100d.txt', 'glove.6B.200d.txt', 'glove.6B.300d.txt', 'glove.840B.300d.txt', 'glove.twitter.27B.25d.txt', 'glove.twitter.27B.50d.txt', 'glove.twitter.27B.100d.txt', 'glove.twitter.27B.200d.txt']
预训练的GloVe模型的命名规范大致是“模型.(数据集.)数据集词数.词向量维度.txt”。更多信息可以参考GloVe和fastText的项目网站[2,3]。下面我们使用基于维基百科子集预训练的50维GloVe词向量。第一次创建预训练词向量实例时会自动下载相应的词向量,因此需要联网。
- In [3]:
- glove_6b50d = text.embedding.create(
- 'glove', pretrained_file_name='glove.6B.50d.txt')
打印词典大小。其中含有40万个词和1个特殊的未知词符号。
- In [4]:
- len(glove_6b50d)
- Out[4]:
- 400001
我们可以通过词来获取它在词典中的索引,也可以通过索引获取词。
- In [5]:
- glove_6b50d.token_to_idx['beautiful'], glove_6b50d.idx_to_token[3367]
- Out[5]:
- (3367, 'beautiful')
10.6.2. 应用预训练词向量
下面我们以GloVe模型为例,展示预训练词向量的应用。
10.6.2.1. 求近义词
这里重新实现“word2vec的实现”一节中介绍过的使用余弦相似度来搜索近义词的算法。为了在求类比词时重用其中的求
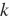 近邻(
近邻(
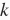 -nearestneighbors)的逻辑,我们将这部分逻辑单独封装在
-nearestneighbors)的逻辑,我们将这部分逻辑单独封装在knn函数中。
- In [6]:
- def knn(W, x, k):
- # 添加的1e-9是为了数值稳定性
- cos = nd.dot(W, x.reshape((-1,))) / (
- (nd.sum(W * W, axis=1) + 1e-9).sqrt() * nd.sum(x * x).sqrt())
- topk = nd.topk(cos, k=k, ret_typ='indices').asnumpy().astype('int32')
- return topk, [cos[i].asscalar() for i in topk]
然后,我们通过预训练词向量实例embed来搜索近义词。
- In [7]:
- def get_similar_tokens(query_token, k, embed):
- topk, cos = knn(embed.idx_to_vec,
- embed.get_vecs_by_tokens([query_token]), k+1)
- for i, c in zip(topk[1:], cos[1:]): # 除去输入词
- print('cosine sim=%.3f: %s' % (c, (embed.idx_to_token[i])))
已创建的预训练词向量实例glove_6b50d的词典中含40万个词和1个特殊的未知词。除去输入词和未知词,我们从中搜索与“chip”语义最相近的3个词。
- In [8]:
- get_similar_tokens('chip', 3, glove_6b50d)
- cosine sim=0.856: chips
- cosine sim=0.749: intel
- cosine sim=0.749: electronics
接下来查找“baby”和“beautiful”的近义词。
- In [9]:
- get_similar_tokens('baby', 3, glove_6b50d)
- cosine sim=0.839: babies
- cosine sim=0.800: boy
- cosine sim=0.792: girl
- In [10]:
- get_similar_tokens('beautiful', 3, glove_6b50d)
- cosine sim=0.921: lovely
- cosine sim=0.893: gorgeous
- cosine sim=0.830: wonderful
10.6.2.2. 求类比词
除了求近义词以外,我们还可以使用预训练词向量求词与词之间的类比关系。例如,“man”(男人):“woman”(女人):: “son”(儿子) :“daughter”(女儿)是一个类比例子:“man”之于“woman”相当于“son”之于“daughter”。求类比词问题可以定义为:对于类比关系中的4个词
 ,给定前3个词
,给定前3个词
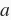 、
、
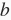 和
和
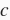 ,求
,求
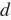 。设词
。设词
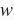 的词向量为
的词向量为
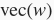 。求类比词的思路是,搜索与
。求类比词的思路是,搜索与
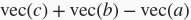 的结果向量最相似的词向量。
的结果向量最相似的词向量。
- In [11]:
- def get_analogy(token_a, token_b, token_c, embed):
- vecs = embed.get_vecs_by_tokens([token_a, token_b, token_c])
- x = vecs[1] - vecs[0] + vecs[2]
- topk, cos = knn(embed.idx_to_vec, x, 1)
- return embed.idx_to_token[topk[0]]
验证一下“男-女”类比。
- In [12]:
- get_analogy('man', 'woman', 'son', glove_6b50d)
- Out[12]:
- 'daughter'
“首都-国家”类比:“beijing”(北京)之于“china”(中国)相当于“tokyo”(东京)之于什么?答案应该是“japan”(日本)。
- In [13]:
- get_analogy('beijing', 'china', 'tokyo', glove_6b50d)
- Out[13]:
- 'japan'
“形容词-形容词最高级”类比:“bad”(坏的)之于“worst”(最坏的)相当于“big”(大的)之于什么?答案应该是“biggest”(最大的)。
- In [14]:
- get_analogy('bad', 'worst', 'big', glove_6b50d)
- Out[14]:
- 'biggest'
“动词一般时-动词过去时”类比:“do”(做)之于“did”(做过)相当于“go”(去)之于什么?答案应该是“went”(去过)。
- In [15]:
- get_analogy('do', 'did', 'go', glove_6b50d)
- Out[15]:
- 'went'
10.6.3. 小结
- 在大规模语料上预训练的词向量常常可以应用于下游自然语言处理任务中。
- 可以应用预训练的词向量求近义词和类比词。
10.6.4. 练习
- 测试一下fastText的结果。值得一提的是,fastText有预训练的中文词向量(
pretrained_file_name='wiki.zh.vec')。 - 如果词典特别大,如何提升近义词或类比词的搜索速度?
10.6.5. 参考文献
[1] GluonNLP工具包。 https://gluon-nlp.mxnet.io/
[2] GloVe项目网站。 https://nlp.stanford.edu/projects/glove/
[3] fastText项目网站。 https://fasttext.cc/
