- 3.12. 权重衰减
- 3.12.1. 方法
- 3.12.2. 高维线性回归实验
- 3.12.3. 从零开始实现
- 3.12.3.1. 初始化模型参数
- 3.12.3.2. 定义L_2范数惩罚项
- 3.12.3.3. 定义训练和测试
- 3.12.3.4. 观察过拟合
- 3.12.3.5. 使用权重衰减
- 3.12.4. 简洁实现
- 3.12.5. 小结
- 3.12.6. 练习
3.12. 权重衰减
上一节中我们观察了过拟合现象,即模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。本节介绍应对过拟合问题的常用方法:权重衰减(weightdecay)。
3.12.1. 方法
权重衰减等价于
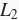 范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述
范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述
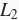 范数正则化,再解释它为何又称权重衰减。
范数正则化,再解释它为何又称权重衰减。
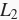 范数正则化在模型原损失函数基础上添加
范数正则化在模型原损失函数基础上添加
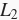 范数惩罚项,从而得到训练所需要最小化的函数。
范数惩罚项,从而得到训练所需要最小化的函数。
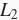 范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以“线性回归”一节中的线性回归损失函数
范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以“线性回归”一节中的线性回归损失函数
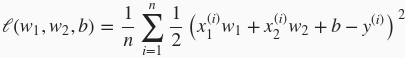
为例,其中
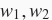 是权重参数,
是权重参数,
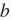 是偏差参数,样本
是偏差参数,样本
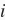 的输入为
的输入为
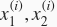 ,标签为
,标签为
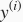 ,样本数为
,样本数为
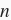 。将权重参数用向量
。将权重参数用向量
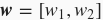 表示,带有
表示,带有
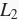 范数惩罚项的新损失函数为
范数惩罚项的新损失函数为
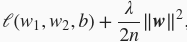
其中超参数
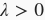 。当权重参数均为0时,惩罚项最小。当
。当权重参数均为0时,惩罚项最小。当
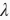 较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当
较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当
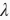 设为0时,惩罚项完全不起作用。上式中
设为0时,惩罚项完全不起作用。上式中
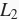 范数平方
范数平方
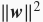 展开后得到
展开后得到
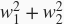 。有了
。有了
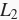 范数惩罚项后,在小批量随机梯度下降中,我们将“线性回归”一节中权重
范数惩罚项后,在小批量随机梯度下降中,我们将“线性回归”一节中权重
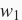 和
和
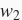 的迭代方式更改为
的迭代方式更改为
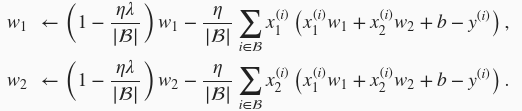
可见,
 范数正则化令权重
范数正则化令权重
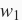 和
和
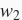 先自乘小于1的数,再减去不含惩罚项的梯度。因此,
先自乘小于1的数,再减去不含惩罚项的梯度。因此,
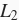 范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
3.12.2. 高维线性回归实验
下面,我们以高维线性回归为例来引入一个过拟合问题,并使用权重衰减来应对过拟合。设数据样本特征的维度为
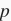 。对于训练数据集和测试数据集中特征为
。对于训练数据集和测试数据集中特征为
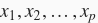 的任一样本,我们使用如下的线性函数来生成该样本的标签:
的任一样本,我们使用如下的线性函数来生成该样本的标签:
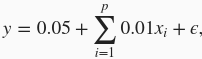
其中噪声项
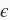 服从均值为0、标准差为0.01的正态分布。为了较容易地观察过拟合,我们考虑高维线性回归问题,如设维度
服从均值为0、标准差为0.01的正态分布。为了较容易地观察过拟合,我们考虑高维线性回归问题,如设维度
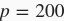 ;同时,我们特意把训练数据集的样本数设低,如20。
;同时,我们特意把训练数据集的样本数设低,如20。
- In [1]:
- %matplotlib inline
- import d2lzh as d2l
- from mxnet import autograd, gluon, init, nd
- from mxnet.gluon import data as gdata, loss as gloss, nn
- n_train, n_test, num_inputs = 20, 100, 200
- true_w, true_b = nd.ones((num_inputs, 1)) * 0.01, 0.05
- features = nd.random.normal(shape=(n_train + n_test, num_inputs))
- labels = nd.dot(features, true_w) + true_b
- labels += nd.random.normal(scale=0.01, shape=labels.shape)
- train_features, test_features = features[:n_train, :], features[n_train:, :]
- train_labels, test_labels = labels[:n_train], labels[n_train:]
3.12.3. 从零开始实现
下面先介绍从零开始实现权重衰减的方法。我们通过在目标函数后添加
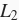 范数惩罚项来实现权重衰减。
范数惩罚项来实现权重衰减。
3.12.3.1. 初始化模型参数
首先,定义随机初始化模型参数的函数。该函数为每个参数都附上梯度。
- In [2]:
- def init_params():
- w = nd.random.normal(scale=1, shape=(num_inputs, 1))
- b = nd.zeros(shape=(1,))
- w.attach_grad()
- b.attach_grad()
- return [w, b]
3.12.3.2. 定义L_2范数惩罚项
下面定义
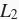 范数惩罚项。这里只惩罚模型的权重参数。
范数惩罚项。这里只惩罚模型的权重参数。
- In [3]:
- def l2_penalty(w):
- return (w**2).sum() / 2
3.12.3.3. 定义训练和测试
下面定义如何在训练数据集和测试数据集上分别训练和测试模型。与前面几节中不同的是,这里在计算最终的损失函数时添加了
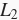 范数惩罚项。
范数惩罚项。
- In [4]:
- batch_size, num_epochs, lr = 1, 100, 0.003
- net, loss = d2l.linreg, d2l.squared_loss
- train_iter = gdata.DataLoader(gdata.ArrayDataset(
- train_features, train_labels), batch_size, shuffle=True)
- def fit_and_plot(lambd):
- w, b = init_params()
- train_ls, test_ls = [], []
- for _ in range(num_epochs):
- for X, y in train_iter:
- with autograd.record():
- # 添加了L2范数惩罚项
- l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
- l.backward()
- d2l.sgd([w, b], lr, batch_size)
- train_ls.append(loss(net(train_features, w, b),
- train_labels).mean().asscalar())
- test_ls.append(loss(net(test_features, w, b),
- test_labels).mean().asscalar())
- d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
- range(1, num_epochs + 1), test_ls, ['train', 'test'])
- print('L2 norm of w:', w.norm().asscalar())
3.12.3.4. 观察过拟合
接下来,让我们训练并测试高维线性回归模型。当lambd设为0时,我们没有使用权重衰减。结果训练误差远小于测试集上的误差。这是典型的过拟合现象。
- In [5]:
- fit_and_plot(lambd=0)

- L2 norm of w: 11.61194
3.12.3.5. 使用权重衰减
下面我们使用权重衰减。可以看出,训练误差虽然有所提高,但测试集上的误差有所下降。过拟合现象得到一定程度的缓解。另外,权重参数的
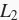 范数比不使用权重衰减时的更小,此时的权重参数更接近0。
范数比不使用权重衰减时的更小,此时的权重参数更接近0。
- In [6]:
- fit_and_plot(lambd=3)

- L2 norm of w: 0.04175589
3.12.4. 简洁实现
这里我们直接在构造Trainer实例时通过wd参数来指定权重衰减超参数。默认下,Gluon会对权重和偏差同时衰减。我们可以分别对权重和偏差构造Trainer实例,从而只对权重衰减。
- In [7]:
- def fit_and_plot_gluon(wd):
- net = nn.Sequential()
- net.add(nn.Dense(1))
- net.initialize(init.Normal(sigma=1))
- # 对权重参数衰减。权重名称一般是以weight结尾
- trainer_w = gluon.Trainer(net.collect_params('.*weight'), 'sgd',
- {'learning_rate': lr, 'wd': wd})
- # 不对偏差参数衰减。偏差名称一般是以bias结尾
- trainer_b = gluon.Trainer(net.collect_params('.*bias'), 'sgd',
- {'learning_rate': lr})
- train_ls, test_ls = [], []
- for _ in range(num_epochs):
- for X, y in train_iter:
- with autograd.record():
- l = loss(net(X), y)
- l.backward()
- # 对两个Trainer实例分别调用step函数,从而分别更新权重和偏差
- trainer_w.step(batch_size)
- trainer_b.step(batch_size)
- train_ls.append(loss(net(train_features),
- train_labels).mean().asscalar())
- test_ls.append(loss(net(test_features),
- test_labels).mean().asscalar())
- d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
- range(1, num_epochs + 1), test_ls, ['train', 'test'])
- print('L2 norm of w:', net[0].weight.data().norm().asscalar())
与从零开始实现权重衰减的实验现象类似,使用权重衰减可以在一定程度上缓解过拟合问题。
- In [8]:
- fit_and_plot_gluon(0)

- L2 norm of w: 13.311798
- In [9]:
- fit_and_plot_gluon(3)

- L2 norm of w: 0.03225094
3.12.5. 小结
- 正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。
- 权重衰减等价于
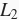 范数正则化,通常会使学到的权重参数的元素较接近0。
范数正则化,通常会使学到的权重参数的元素较接近0。 - 权重衰减可以通过Gluon的
wd超参数来指定。 - 可以定义多个
Trainer实例对不同的模型参数使用不同的迭代方法。
3.12.6. 练习
- 回顾一下训练误差和泛化误差的关系。除了权重衰减、增大训练量以及使用复杂度合适的模型,你还能想到哪些办法来应对过拟合?
- 如果你了解贝叶斯统计,你觉得权重衰减对应贝叶斯统计里的哪个重要概念?
- 调节实验中的权重衰减超参数,观察并分析实验结果。
