- 4.2. 模型参数的访问、初始化和共享
- 4.2.1. 访问模型参数
- 4.2.2. 初始化模型参数
- 4.2.3. 自定义初始化方法
- 4.2.4. 共享模型参数
- 4.2.5. 小结
- 4.2.6. 练习
4.2. 模型参数的访问、初始化和共享
在“线性回归的简洁实现”一节中,我们通过init模块来初始化模型的全部参数。我们也介绍了访问模型参数的简单方法。本节将深入讲解如何访问和初始化模型参数,以及如何在多个层之间共享同一份模型参数。
我们先定义一个与上一节中相同的含单隐藏层的多层感知机。我们依然使用默认方式初始化它的参数,并做一次前向计算。与之前不同的是,在这里我们从MXNet中导入了init模块,它包含了多种模型初始化方法。
- In [1]:
- from mxnet import init, nd
- from mxnet.gluon import nn
- net = nn.Sequential()
- net.add(nn.Dense(256, activation='relu'))
- net.add(nn.Dense(10))
- net.initialize() # 使用默认初始化方式
- X = nd.random.uniform(shape=(2, 20))
- Y = net(X) # 前向计算
4.2.1. 访问模型参数
对于使用Sequential类构造的神经网络,我们可以通过方括号[]来访问网络的任一层。回忆一下上一节中提到的Sequential类与Block类的继承关系。对于Sequential实例中含模型参数的层,我们可以通过Block类的params属性来访问该层包含的所有参数。下面,访问多层感知机net中隐藏层的所有参数。索引0表示隐藏层为Sequential实例最先添加的层。
- In [2]:
- net[0].params, type(net[0].params)
- Out[2]:
- (dense0_ (
- Parameter dense0_weight (shape=(256, 20), dtype=float32)
- Parameter dense0_bias (shape=(256,), dtype=float32)
- ), mxnet.gluon.parameter.ParameterDict)
可以看到,我们得到了一个由参数名称映射到参数实例的字典(类型为ParameterDict类)。其中权重参数的名称为dense0weight,它由net[0]的名称(dense0)和自己的变量名(weight)组成。而且可以看到,该参数的形状为(256,20),且数据类型为32位浮点数(float32)。为了访问特定参数,我们既可以通过名字来访问字典里的元素,也可以直接使用它的变量名。下面两种方法是等价的,但通常后者的代码可读性更好。
- In [3]:
- net[0].params['dense0_weight'], net[0].weight
- Out[3]:
- (Parameter dense0_weight (shape=(256, 20), dtype=float32),
- Parameter dense0_weight (shape=(256, 20), dtype=float32))
Gluon里参数类型为Parameter类,它包含参数和梯度的数值,可以分别通过data函数和grad函数来访问。因为我们随机初始化了权重,所以权重参数是一个由随机数组成的形状为(256,20)的NDArray。
- In [4]:
- net[0].weight.data()
- Out[4]:
- [[ 0.06700657 -0.00369488 0.0418822 ... -0.05517294 -0.01194733
- -0.00369594]
- [-0.03296221 -0.04391347 0.03839272 ... 0.05636378 0.02545484
- -0.007007 ]
- [-0.0196689 0.01582889 -0.00881553 ... 0.01509629 -0.01908049
- -0.02449339]
- ...
- [ 0.00010955 0.0439323 -0.04911506 ... 0.06975312 0.0449558
- -0.03283203]
- [ 0.04106557 0.05671307 -0.00066976 ... 0.06387014 -0.01292654
- 0.00974177]
- [ 0.00297424 -0.0281784 -0.06881659 ... -0.04047417 0.00457048
- 0.05696651]]
- <NDArray 256x20 @cpu(0)>
权重梯度的形状和权重的形状一样。因为我们还没有进行反向传播计算,所以梯度的值全为0。
- In [5]:
- net[0].weight.grad()
- Out[5]:
- [[0. 0. 0. ... 0. 0. 0.]
- [0. 0. 0. ... 0. 0. 0.]
- [0. 0. 0. ... 0. 0. 0.]
- ...
- [0. 0. 0. ... 0. 0. 0.]
- [0. 0. 0. ... 0. 0. 0.]
- [0. 0. 0. ... 0. 0. 0.]]
- <NDArray 256x20 @cpu(0)>
类似地,我们可以访问其他层的参数,如输出层的偏差值。
- In [6]:
- net[1].bias.data()
- Out[6]:
- [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
- <NDArray 10 @cpu(0)>
最后,我们可以使用collect_params函数来获取net变量所有嵌套(例如通过add函数嵌套)的层所包含的所有参数。它返回的同样是一个由参数名称到参数实例的字典。
- In [7]:
- net.collect_params()
- Out[7]:
- sequential0_ (
- Parameter dense0_weight (shape=(256, 20), dtype=float32)
- Parameter dense0_bias (shape=(256,), dtype=float32)
- Parameter dense1_weight (shape=(10, 256), dtype=float32)
- Parameter dense1_bias (shape=(10,), dtype=float32)
- )
这个函数可以通过正则表达式来匹配参数名,从而筛选需要的参数。
- In [8]:
- net.collect_params('.*weight')
- Out[8]:
- sequential0_ (
- Parameter dense0_weight (shape=(256, 20), dtype=float32)
- Parameter dense1_weight (shape=(10, 256), dtype=float32)
- )
4.2.2. 初始化模型参数
我们在“数值稳定性和模型初始化”一节中描述了模型的默认初始化方法:权重参数元素为[-0.07,0.07]之间均匀分布的随机数,偏差参数则全为0。但我们经常需要使用其他方法来初始化权重。MXNet的init模块里提供了多种预设的初始化方法。在下面的例子中,我们将权重参数初始化成均值为0、标准差为0.01的正态分布随机数,并依然将偏差参数清零。
- In [9]:
- # 非首次对模型初始化需要指定force_reinit为真
- net.initialize(init=init.Normal(sigma=0.01), force_reinit=True)
- net[0].weight.data()[0]
- Out[9]:
- [ 0.01074176 0.00066428 0.00848699 -0.0080038 -0.00168822 0.00936328
- 0.00357444 0.00779328 -0.01010307 -0.00391573 0.01316619 -0.00432926
- 0.0071536 0.00925416 -0.00904951 -0.00074684 0.0082254 -0.01878511
- 0.00885884 0.01911872]
- <NDArray 20 @cpu(0)>
下面使用常数来初始化权重参数。
- In [10]:
- net.initialize(init=init.Constant(1), force_reinit=True)
- net[0].weight.data()[0]
- Out[10]:
- [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
- <NDArray 20 @cpu(0)>
如果只想对某个特定参数进行初始化,我们可以调用Parameter类的initialize函数,它与Block类提供的initialize函数的使用方法一致。下例中我们对隐藏层的权重使用Xavier随机初始化方法。
- In [11]:
- net[0].weight.initialize(init=init.Xavier(), force_reinit=True)
- net[0].weight.data()[0]
- Out[11]:
- [ 0.00512482 -0.06579044 -0.10849719 -0.09586414 0.06394844 0.06029618
- -0.03065033 -0.01086642 0.01929168 0.1003869 -0.09339568 -0.08703034
- -0.10472868 -0.09879824 -0.00352201 -0.11063069 -0.04257748 0.06548801
- 0.12987629 -0.13846186]
- <NDArray 20 @cpu(0)>
4.2.3. 自定义初始化方法
有时候我们需要的初始化方法并没有在init模块中提供。这时,可以实现一个Initializer类的子类,从而能够像使用其他初始化方法那样使用它。通常,我们只需要实现_init_weight这个函数,并将其传入的NDArray修改成初始化的结果。在下面的例子里,我们令权重有一半概率初始化为0,有另一半概率初始化为
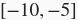 和
和
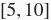 两个区间里均匀分布的随机数。
两个区间里均匀分布的随机数。
- In [12]:
- class MyInit(init.Initializer):
- def _init_weight(self, name, data):
- print('Init', name, data.shape)
- data[:] = nd.random.uniform(low=-10, high=10, shape=data.shape)
- data *= data.abs() >= 5
- net.initialize(MyInit(), force_reinit=True)
- net[0].weight.data()[0]
- Init dense0_weight (256, 20)
- Init dense1_weight (10, 256)
- Out[12]:
- [-5.3659673 7.5773945 8.986376 -0. 8.827555 0.
- 5.9840508 -0. 0. 0. 7.4857597 -0.
- -0. 6.8910007 6.9788704 -6.1131554 0. 5.4665203
- -9.735263 9.485172 ]
- <NDArray 20 @cpu(0)>
此外,我们还可以通过Parameter类的set_data函数来直接改写模型参数。例如,在下例中我们将隐藏层参数在现有的基础上加1。
- In [13]:
- net[0].weight.set_data(net[0].weight.data() + 1)
- net[0].weight.data()[0]
- Out[13]:
- [-4.3659673 8.5773945 9.986376 1. 9.827555 1.
- 6.9840508 1. 1. 1. 8.48576 1.
- 1. 7.8910007 7.9788704 -5.1131554 1. 6.4665203
- -8.735263 10.485172 ]
- <NDArray 20 @cpu(0)>
4.2.4. 共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。“模型构造”一节介绍了如何在Block类的forward函数里多次调用同一个层来计算。这里再介绍另外一种方法,它在构造层的时候指定使用特定的参数。如果不同层使用同一份参数,那么它们在前向计算和反向传播时都会共享相同的参数。在下面的例子里,我们让模型的第二隐藏层(shared变量)和第三隐藏层共享模型参数。
- In [14]:
- net = nn.Sequential()
- shared = nn.Dense(8, activation='relu')
- net.add(nn.Dense(8, activation='relu'),
- shared,
- nn.Dense(8, activation='relu', params=shared.params),
- nn.Dense(10))
- net.initialize()
- X = nd.random.uniform(shape=(2, 20))
- net(X)
- net[1].weight.data()[0] == net[2].weight.data()[0]
- Out[14]:
- [1. 1. 1. 1. 1. 1. 1. 1.]
- <NDArray 8 @cpu(0)>
我们在构造第三隐藏层时通过params来指定它使用第二隐藏层的参数。因为模型参数里包含了梯度,所以在反向传播计算时,第二隐藏层和第三隐藏层的梯度都会被累加在shared.params.grad()里。
4.2.5. 小结
- 有多种方法来访问、初始化和共享模型参数。
- 可以自定义初始化方法。
4.2.6. 练习
- 查阅有关
init模块的MXNet文档,了解不同的参数初始化方法。 - 尝试在
net.initialize()后、net(X)前访问模型参数,观察模型参数的形状。 - 构造一个含共享参数层的多层感知机并训练。在训练过程中,观察每一层的模型参数和梯度。
