- 8.2. 异步计算
- 8.2.1. MXNet中的异步计算
- 8.2.2. 用同步函数让前端等待计算结果
- 8.2.3. 使用异步计算提升计算性能
- 8.2.4. 异步计算对内存的影响
- 8.2.5. 小结
- 8.2.6. 练习
8.2. 异步计算
MXNet使用异步计算来提升计算性能。理解它的工作原理既有助于开发更高效的程序,又有助于在内存资源有限的情况下主动降低计算性能从而减小内存开销。我们先导入本节中实验需要的包或模块。
- In [1]:
- from mxnet import autograd, gluon, nd
- from mxnet.gluon import loss as gloss, nn
- import os
- import subprocess
- import time
8.2.1. MXNet中的异步计算
广义上讲,MXNet包括用户直接用来交互的前端和系统用来执行计算的后端。例如,用户可以使用不同的前端语言编写MXNet程序,如Python、R、Scala和C++。无论使用何种前端编程语言,MXNet程序的执行主要都发生在C++实现的后端。换句话说,用户写好的前端MXNet程序会传给后端执行计算。后端有自己的线程在队列中不断收集任务并执行它们。
MXNet通过前端线程和后端线程的交互实现异步计算。异步计算指,前端线程无须等待当前指令从后端线程返回结果就继续执行后面的指令。为了便于解释,假设Python前端线程调用以下4条指令。
- In [2]:
- a = nd.ones((1, 2))
- b = nd.ones((1, 2))
- c = a * b + 2
- c
- Out[2]:
- [[3. 3.]]
- <NDArray 1x2 @cpu(0)>
在异步计算中,Python前端线程执行前3条语句的时候,仅仅是把任务放进后端的队列里就返回了。当最后一条语句需要打印计算结果时,Python前端线程会等待C++后端线程把变量c的结果计算完。此设计的一个好处是,这里的Python前端线程不需要做实际计算。因此,无论Python的性能如何,它对整个程序性能的影响很小。只要C++后端足够高效,那么不管前端编程语言性能如何,MXNet都可以提供一致的高性能。
为了演示异步计算的性能,我们先实现一个简单的计时类。
- In [3]:
- class Benchmark(): # 本类已保存在d2lzh包中方便以后使用
- def __init__(self, prefix=None):
- self.prefix = prefix + ' ' if prefix else ''
- def __enter__(self):
- self.start = time.time()
- def __exit__(self, *args):
- print('%stime: %.4f sec' % (self.prefix, time.time() - self.start))
下面的例子通过计时来展示异步计算的效果。可以看到,当y = nd.dot(x, x).sum()返回的时候并没有等待变量y真正被计算完。只有当print函数需要打印变量y时才必须等待它计算完。
- In [4]:
- with Benchmark('Workloads are queued.'):
- x = nd.random.uniform(shape=(2000, 2000))
- y = nd.dot(x, x).sum()
- with Benchmark('Workloads are finished.'):
- print('sum =', y)
- Workloads are queued. time: 0.0007 sec
- sum =
- [2.0003661e+09]
- <NDArray 1 @cpu(0)>
- Workloads are finished. time: 0.1712 sec
的确,除非我们需要打印或者保存计算结果,否则我们基本无须关心目前结果在内存中是否已经计算好了。只要数据是保存在NDArray里并使用MXNet提供的运算符,MXNet将默认使用异步计算来获取高计算性能。
8.2.2. 用同步函数让前端等待计算结果
除了刚刚介绍的print函数外,我们还有其他方法让前端线程等待后端的计算结果完成。我们可以使用wait_to_read函数让前端等待某个的NDArray的计算结果完成,再执行前端中后面的语句。或者,我们可以用waitall函数令前端等待前面所有计算结果完成。后者是性能测试中常用的方法。
下面是使用wait_to_read函数的例子。输出用时包含了变量y的计算时间。
- In [5]:
- with Benchmark():
- y = nd.dot(x, x)
- y.wait_to_read()
- time: 0.0646 sec
下面是使用waitall函数的例子。输出用时包含了变量y和变量z的计算时间。
- In [6]:
- with Benchmark():
- y = nd.dot(x, x)
- z = nd.dot(x, x)
- nd.waitall()
- time: 0.1269 sec
此外,任何将NDArray转换成其他不支持异步计算的数据结构的操作都会让前端等待计算结果。例如,当我们调用asnumpy函数和asscalar函数时:
- In [7]:
- with Benchmark():
- y = nd.dot(x, x)
- y.asnumpy()
- time: 0.0670 sec
- In [8]:
- with Benchmark():
- y = nd.dot(x, x)
- y.norm().asscalar()
- time: 0.1585 sec
上面介绍的wait_to_read函数、waitall函数、asnumpy函数、asscalar函数和print函数会触发让前端等待后端计算结果的行为。这类函数通常称为同步函数。
8.2.3. 使用异步计算提升计算性能
在下面的例子中,我们用for循环不断对变量y赋值。当在for循环内使用同步函数wait_to_read时,每次赋值不使用异步计算;当在for循环外使用同步函数waitall时,则使用异步计算。
- In [9]:
- with Benchmark('synchronous.'):
- for _ in range(1000):
- y = x + 1
- y.wait_to_read()
- with Benchmark('asynchronous.'):
- for _ in range(1000):
- y = x + 1
- nd.waitall()
- synchronous. time: 0.5856 sec
- asynchronous. time: 0.3696 sec
我们观察到,使用异步计算能提升一定的计算性能。为了解释这一现象,让我们对Python前端线程和C++后端线程的交互稍作简化。在每一次循环中,前端和后端的交互大约可以分为3个阶段:
- 前端令后端将计算任务
y = x + 1放进队列; - 后端从队列中获取计算任务并执行真正的计算;
- 后端将计算结果返回给前端。 我们将这3个阶段的耗时分别设为
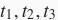 。如果不使用异步计算,执行1000次计算的总耗时大约为
。如果不使用异步计算,执行1000次计算的总耗时大约为
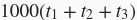 ;如果使用异步计算,由于每次循环中前端都无须等待后端返回计算结果,执行1000次计算的总耗时可以降为
;如果使用异步计算,由于每次循环中前端都无须等待后端返回计算结果,执行1000次计算的总耗时可以降为
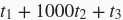 (假设
(假设
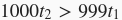 )。
)。
8.2.4. 异步计算对内存的影响
为了解释异步计算对内存使用的影响,让我们先回忆一下前面章节的内容。在前面章节中实现的模型训练过程中,我们通常会在每个小批量上评测一下模型,如模型的损失或者精度。细心的读者也许已经发现了,这类评测常用到同步函数,如asscalar函数或者asnumpy函数。如果去掉这些同步函数,前端会将大量的小批量计算任务在极短的时间内丢给后端,从而可能导致占用更多内存。当我们在每个小批量上都使用同步函数时,前端在每次迭代时仅会将一个小批量的任务丢给后端执行计算,并通常会减小内存占用。
由于深度学习模型通常比较大,而内存资源通常有限,建议大家在训练模型时对每个小批量都使用同步函数,例如,用asscalar函数或者asnumpy函数评价模型的表现。类似地,在使用模型预测时,为了减小内存的占用,也建议大家对每个小批量预测时都使用同步函数,例如,直接打印出当前小批量的预测结果。
下面我们来演示异步计算对内存的影响。我们先定义一个数据获取函数data_iter,它会从被调用时开始计时,并定期打印到目前为止获取数据批量的总耗时。
- In [10]:
- def data_iter():
- start = time.time()
- num_batches, batch_size = 100, 1024
- for i in range(num_batches):
- X = nd.random.normal(shape=(batch_size, 512))
- y = nd.ones((batch_size,))
- yield X, y
- if (i + 1) % 50 == 0:
- print('batch %d, time %f sec' % (i + 1, time.time() - start))
下面定义多层感知机、优化算法和损失函数。
- In [11]:
- net = nn.Sequential()
- net.add(nn.Dense(2048, activation='relu'),
- nn.Dense(512, activation='relu'),
- nn.Dense(1))
- net.initialize()
- trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.005})
- loss = gloss.L2Loss()
这里定义辅助函数来监测内存的使用。需要注意的是,这个函数只能在Linux或macOS上运行。
- In [12]:
- def get_mem():
- res = subprocess.check_output(['ps', 'u', '-p', str(os.getpid())])
- return int(str(res).split()[15]) / 1e3
现在我们可以做测试了。我们先试运行一次,让系统把net的参数初始化。有关初始化的讨论可参见“模型参数的延后初始化”一节。
- In [13]:
- for X, y in data_iter():
- break
- loss(y, net(X)).wait_to_read()
对于训练模型net来说,我们可以自然地使用同步函数asscalar将每个小批量的损失从NDArray格式中取出,并打印每个迭代周期后的模型损失。此时,每个小批量的生成间隔较长,不过内存开销较小。
- In [14]:
- l_sum, mem = 0, get_mem()
- for X, y in data_iter():
- with autograd.record():
- l = loss(y, net(X))
- l_sum += l.mean().asscalar() # 使用同步函数asscalar
- l.backward()
- trainer.step(X.shape[0])
- nd.waitall()
- print('increased memory: %f MB' % (get_mem() - mem))
- batch 50, time 3.371737 sec
- batch 100, time 6.779474 sec
- increased memory: 2.896000 MB
如果去掉同步函数,虽然每个小批量的生成间隔较短,但训练过程中可能会导致内存占用较高。这是因为在默认异步计算下,前端会将所有小批量计算在短时间内全部丢给后端。这可能在内存积压大量中间结果无法释放。实验中我们看到,不到一秒,所有数据(X和y)就都已经产生。但因为训练速度没有跟上,所以这些数据只能放在内存里不能及时清除,从而占用额外内存。
- In [15]:
- mem = get_mem()
- for X, y in data_iter():
- with autograd.record():
- l = loss(y, net(X))
- l.backward()
- trainer.step(X.shape[0])
- nd.waitall()
- print('increased memory: %f MB' % (get_mem() - mem))
- batch 50, time 0.079871 sec
- batch 100, time 0.159572 sec
- increased memory: 198.924000 MB
8.2.5. 小结
- MXNet包括用户直接用来交互的前端和系统用来执行计算的后端。
- MXNet能够通过异步计算提升计算性能。
- 建议使用每个小批量训练或预测时至少使用一个同步函数,从而避免在短时间内将过多计算任务丢给后端。
8.2.6. 练习
- 在“使用异步计算提升计算性能”一节中,我们提到使用异步计算可以使执行1000次计算的总耗时降为
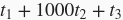 。这里为什么要假设
。这里为什么要假设
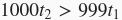 ?
?
