- 4.6. GPU计算
- 4.6.1. 计算设备
- 4.6.2. NDArray的GPU计算
- 4.6.2.1. GPU上的存储
- 4.6.2.2. GPU上的计算
- 4.6.3. Gluon的GPU计算
- 4.6.4. 小结
- 4.6.5. 练习
- 4.6.6. 参考文献
4.6. GPU计算
到目前为止,我们一直在使用CPU计算。对复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够高效。在本节中,我们将介绍如何使用单块NVIDIAGPU来计算。首先,需要确保已经安装好了至少一块NVIDIAGPU。然后,下载CUDA并按照提示设置好相应的路径(可参考附录中“使用AWS运行代码”一节)。这些准备工作都完成后,下面就可以通过nvidia-smi命令来查看显卡信息了。
- In [1]:
- !nvidia-smi # 对Linux/macOS用户有效
- Mon May 13 00:57:57 2019
- +-----------------------------------------------------------------------------+
- | NVIDIA-SMI 410.48 Driver Version: 410.48 |
- |-------------------------------+----------------------+----------------------+
- | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
- | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
- |===============================+======================+======================|
- | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 |
- | N/A 61C P0 44W / 300W | 0MiB / 16130MiB | 0% Default |
- +-------------------------------+----------------------+----------------------+
- | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 |
- | N/A 44C P0 39W / 300W | 0MiB / 16130MiB | 0% Default |
- +-------------------------------+----------------------+----------------------+
- | 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 |
- | N/A 39C P0 42W / 300W | 0MiB / 16130MiB | 0% Default |
- +-------------------------------+----------------------+----------------------+
- | 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
- | N/A 37C P0 40W / 300W | 0MiB / 16130MiB | 0% Default |
- +-------------------------------+----------------------+----------------------+
- +-----------------------------------------------------------------------------+
- | Processes: GPU Memory |
- | GPU PID Type Process name Usage |
- |=============================================================================|
- | No running processes found |
- +-----------------------------------------------------------------------------+
接下来,我们需要确认安装了MXNet的GPU版本。安装方法见“获取和运行本书的代码”一节。运行本节中的程序需要至少2块GPU。
4.6.1. 计算设备
MXNet可以指定用来存储和计算的设备,如使用内存的CPU或者使用显存的GPU。默认情况下,MXNet会将数据创建在内存,然后利用CPU来计算。在MXNet中,mx.cpu()(或者在括号里填任意整数)表示所有的物理CPU和内存。这意味着,MXNet的计算会尽量使用所有的CPU核。但mx.gpu()只代表一块GPU和相应的显存。如果有多块GPU,我们用mx.gpu(i)来表示第
 块GPU及相应的显存(
块GPU及相应的显存(
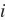 从0开始)且
从0开始)且mx.gpu(0)和mx.gpu()等价。
- In [2]:
- import mxnet as mx
- from mxnet import nd
- from mxnet.gluon import nn
- mx.cpu(), mx.gpu(), mx.gpu(1)
- Out[2]:
- (cpu(0), gpu(0), gpu(1))
4.6.2. NDArray的GPU计算
在默认情况下,NDArray存在内存上。因此,之前我们每次打印NDArray的时候都会看到@cpu(0)这个标识。
- In [3]:
- x = nd.array([1, 2, 3])
- x
- Out[3]:
- [1. 2. 3.]
- <NDArray 3 @cpu(0)>
我们可以通过NDArray的context属性来查看该NDArray所在的设备。
- In [4]:
- x.context
- Out[4]:
- cpu(0)
4.6.2.1. GPU上的存储
我们有多种方法将NDArray存储在显存上。例如,我们可以在创建NDArray的时候通过ctx参数指定存储设备。下面我们将NDArray变量a创建在gpu(0)上。注意,在打印a时,设备信息变成了@gpu(0)。创建在显存上的NDArray只消耗同一块显卡的显存。我们可以通过nvidia-smi命令查看显存的使用情况。通常,我们需要确保不创建超过显存上限的数据。
- In [5]:
- a = nd.array([1, 2, 3], ctx=mx.gpu())
- a
- Out[5]:
- [1. 2. 3.]
- <NDArray 3 @gpu(0)>
假设至少有2块GPU,下面代码将会在gpu(1)上创建随机数组。
- In [6]:
- B = nd.random.uniform(shape=(2, 3), ctx=mx.gpu(1))
- B
- Out[6]:
- [[0.59119 0.313164 0.76352036]
- [0.9731786 0.35454726 0.11677533]]
- <NDArray 2x3 @gpu(1)>
除了在创建时指定,我们也可以通过copyto函数和as_in_context函数在设备之间传输数据。下面我们将内存上的NDArray变量x复制到gpu(0)上。
- In [7]:
- y = x.copyto(mx.gpu())
- y
- Out[7]:
- [1. 2. 3.]
- <NDArray 3 @gpu(0)>
- In [8]:
- z = x.as_in_context(mx.gpu())
- z
- Out[8]:
- [1. 2. 3.]
- <NDArray 3 @gpu(0)>
需要区分的是,如果源变量和目标变量的context一致,as_in_context函数使目标变量和源变量共享源变量的内存或显存。
- In [9]:
- y.as_in_context(mx.gpu()) is y
- Out[9]:
- True
而copyto函数总是为目标变量开新的内存或显存。
- In [10]:
- y.copyto(mx.gpu()) is y
- Out[10]:
- False
4.6.2.2. GPU上的计算
MXNet的计算会在数据的context属性所指定的设备上执行。为了使用GPU计算,我们只需要事先将数据存储在显存上。计算结果会自动保存在同一块显卡的显存上。
- In [11]:
- (z + 2).exp() * y
- Out[11]:
- [ 20.085537 109.1963 445.2395 ]
- <NDArray 3 @gpu(0)>
注意,MXNet要求计算的所有输入数据都在内存或同一块显卡的显存上。这样设计的原因是CPU和不同的GPU之间的数据交互通常比较耗时。因此,MXNet希望用户确切地指明计算的输入数据都在内存或同一块显卡的显存上。例如,如果将内存上的NDArray变量x和显存上的NDArray变量y做运算,会出现错误信息。当我们打印NDArray或将NDArray转换成NumPy格式时,如果数据不在内存里,MXNet会将它先复制到内存,从而造成额外的传输开销。
4.6.3. Gluon的GPU计算
同NDArray类似,Gluon的模型可以在初始化时通过ctx参数指定设备。下面的代码将模型参数初始化在显存上。
- In [12]:
- net = nn.Sequential()
- net.add(nn.Dense(1))
- net.initialize(ctx=mx.gpu())
当输入是显存上的NDArray时,Gluon会在同一块显卡的显存上计算结果。
- In [13]:
- net(y)
- Out[13]:
- [[0.0068339 ]
- [0.01366779]
- [0.02050169]]
- <NDArray 3x1 @gpu(0)>
下面我们确认一下模型参数存储在同一块显卡的显存上。
- In [14]:
- net[0].weight.data()
- Out[14]:
- [[0.0068339]]
- <NDArray 1x1 @gpu(0)>
4.6.4. 小结
- MXNet可以指定用来存储和计算的设备,如使用内存的CPU或者使用显存的GPU。在默认情况下,MXNet会将数据创建在内存,然后利用CPU来计算。
- MXNet要求计算的所有输入数据都在内存或同一块显卡的显存上。
4.6.5. 练习
- 试试大一点儿的计算任务,如大矩阵的乘法,看看使用CPU和GPU的速度区别。如果是计算量很小的任务呢?
- GPU上应如何读写模型参数?
4.6.6. 参考文献
[1] CUDA下载地址。 https://developer.nvidia.com/cuda-downloads
