- 6.4. 循环神经网络的从零开始实现
- 6.4.1. one-hot向量
- 6.4.2. 初始化模型参数
- 6.4.3. 定义模型
- 6.4.4. 定义预测函数
- 6.4.5. 裁剪梯度
- 6.4.6. 困惑度
- 6.4.7. 定义模型训练函数
- 6.4.8. 训练模型并创作歌词
- 6.4.9. 小结
- 6.4.10. 练习
6.4. 循环神经网络的从零开始实现
在本节中,我们将从零开始实现一个基于字符级循环神经网络的语言模型,并在周杰伦专辑歌词数据集上训练一个模型来进行歌词创作。首先,我们读取周杰伦专辑歌词数据集:
- In [1]:
- import d2lzh as d2l
- import math
- from mxnet import autograd, nd
- from mxnet.gluon import loss as gloss
- import time
- (corpus_indices, char_to_idx, idx_to_char,
- vocab_size) = d2l.load_data_jay_lyrics()
6.4.1. one-hot向量
为了将词表示成向量输入到神经网络,一个简单的办法是使用one-hot向量。假设词典中不同字符的数量为
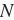 (即词典大小
(即词典大小vocab_size),每个字符已经同一个从0到
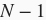 的连续整数值索引一一对应。如果一个字符的索引是整数
的连续整数值索引一一对应。如果一个字符的索引是整数
 ,那么我们创建一个全0的长为
,那么我们创建一个全0的长为
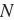 的向量,并将其位置为
的向量,并将其位置为
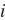 的元素设成1。该向量就是对原字符的one-hot向量。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小。
的元素设成1。该向量就是对原字符的one-hot向量。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小。
- In [2]:
- nd.one_hot(nd.array([0, 2]), vocab_size)
- Out[2]:
- [[1. 0. 0. ... 0. 0. 0.]
- [0. 0. 1. ... 0. 0. 0.]]
- <NDArray 2x1027 @cpu(0)>
我们每次采样的小批量的形状是(批量大小,时间步数)。下面的函数将这样的小批量变换成数个可以输入进网络的形状为(批量大小,词典大小)的矩阵,矩阵个数等于时间步数。也就是说,时间步
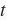 的输入为
的输入为
 ,其中
,其中
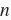 为批量大小,
为批量大小,
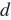 为输入个数,即one-hot向量长度(词典大小)。
为输入个数,即one-hot向量长度(词典大小)。
- In [3]:
- def to_onehot(X, size): # 本函数已保存在d2lzh包中方便以后使用
- return [nd.one_hot(x, size) for x in X.T]
- X = nd.arange(10).reshape((2, 5))
- inputs = to_onehot(X, vocab_size)
- len(inputs), inputs[0].shape
- Out[3]:
- (5, (2, 1027))
6.4.2. 初始化模型参数
接下来,我们初始化模型参数。隐藏单元个数 num_hiddens是一个超参数。
- In [4]:
- num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
- ctx = d2l.try_gpu()
- print('will use', ctx)
- def get_params():
- def _one(shape):
- return nd.random.normal(scale=0.01, shape=shape, ctx=ctx)
- # 隐藏层参数
- W_xh = _one((num_inputs, num_hiddens))
- W_hh = _one((num_hiddens, num_hiddens))
- b_h = nd.zeros(num_hiddens, ctx=ctx)
- # 输出层参数
- W_hq = _one((num_hiddens, num_outputs))
- b_q = nd.zeros(num_outputs, ctx=ctx)
- # 附上梯度
- params = [W_xh, W_hh, b_h, W_hq, b_q]
- for param in params:
- param.attach_grad()
- return params
- will use gpu(0)
6.4.3. 定义模型
我们根据循环神经网络的计算表达式实现该模型。首先定义init_rnn_state函数来返回初始化的隐藏状态。它返回由一个形状为(批量大小,隐藏单元个数)的值为0的NDArray组成的元组。使用元组是为了更便于处理隐藏状态含有多个NDArray的情况。
- In [5]:
- def init_rnn_state(batch_size, num_hiddens, ctx):
- return (nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx), )
下面的rnn函数定义了在一个时间步里如何计算隐藏状态和输出。这里的激活函数使用了tanh函数。“多层感知机”一节中介绍过,当元素在实数域上均匀分布时,tanh函数值的均值为0。
- In [6]:
- def rnn(inputs, state, params):
- # inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
- W_xh, W_hh, b_h, W_hq, b_q = params
- H, = state
- outputs = []
- for X in inputs:
- H = nd.tanh(nd.dot(X, W_xh) + nd.dot(H, W_hh) + b_h)
- Y = nd.dot(H, W_hq) + b_q
- outputs.append(Y)
- return outputs, (H,)
做个简单的测试来观察输出结果的个数(时间步数),以及第一个时间步的输出层输出的形状和隐藏状态的形状。
- In [7]:
- state = init_rnn_state(X.shape[0], num_hiddens, ctx)
- inputs = to_onehot(X.as_in_context(ctx), vocab_size)
- params = get_params()
- outputs, state_new = rnn(inputs, state, params)
- len(outputs), outputs[0].shape, state_new[0].shape
- Out[7]:
- (5, (2, 1027), (2, 256))
6.4.4. 定义预测函数
以下函数基于前缀prefix(含有数个字符的字符串)来预测接下来的num_chars个字符。这个函数稍显复杂,其中我们将循环神经单元rnn设置成了函数参数,这样在后面小节介绍其他循环神经网络时能重复使用这个函数。
- In [8]:
- # 本函数已保存在d2lzh包中方便以后使用
- def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
- num_hiddens, vocab_size, ctx, idx_to_char, char_to_idx):
- state = init_rnn_state(1, num_hiddens, ctx)
- output = [char_to_idx[prefix[0]]]
- for t in range(num_chars + len(prefix) - 1):
- # 将上一时间步的输出作为当前时间步的输入
- X = to_onehot(nd.array([output[-1]], ctx=ctx), vocab_size)
- # 计算输出和更新隐藏状态
- (Y, state) = rnn(X, state, params)
- # 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
- if t < len(prefix) - 1:
- output.append(char_to_idx[prefix[t + 1]])
- else:
- output.append(int(Y[0].argmax(axis=1).asscalar()))
- return ''.join([idx_to_char[i] for i in output])
我们先测试一下predict_rnn函数。我们将根据前缀“分开”创作长度为10个字符(不考虑前缀长度)的一段歌词。因为模型参数为随机值,所以预测结果也是随机的。
- In [9]:
- predict_rnn('分开', 10, rnn, params, init_rnn_state, num_hiddens, vocab_size,
- ctx, idx_to_char, char_to_idx)
- Out[9]:
- '分开习占试辛落所线实小林'
6.4.5. 裁剪梯度
循环神经网络中较容易出现梯度衰减或梯度爆炸。我们会在“通过时间反向传播”一节中解释原因。为了应对梯度爆炸,我们可以裁剪梯度(clipgradient)。假设我们把所有模型参数梯度的元素拼接成一个向量
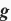 ,并设裁剪的阈值是
,并设裁剪的阈值是
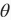 。裁剪后的梯度
。裁剪后的梯度
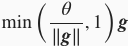
的
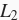 范数不超过
范数不超过
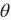 。
。
- In [10]:
- # 本函数已保存在d2lzh包中方便以后使用
- def grad_clipping(params, theta, ctx):
- norm = nd.array([0], ctx)
- for param in params:
- norm += (param.grad ** 2).sum()
- norm = norm.sqrt().asscalar()
- if norm > theta:
- for param in params:
- param.grad[:] *= theta / norm
6.4.6. 困惑度
我们通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下“softmax回归”一节中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小
vocab_size。
6.4.7. 定义模型训练函数
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
- 使用困惑度评价模型。
- 在迭代模型参数前裁剪梯度。
- 对时序数据采用不同采样方法将导致隐藏状态初始化的不同。相关讨论可参考“语言模型数据集(周杰伦专辑歌词)”一节。 另外,考虑到后面将介绍的其他循环神经网络,为了更通用,这里的函数实现更长一些。
- In [11]:
- # 本函数已保存在d2lzh包中方便以后使用
- def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
- vocab_size, ctx, corpus_indices, idx_to_char,
- char_to_idx, is_random_iter, num_epochs, num_steps,
- lr, clipping_theta, batch_size, pred_period,
- pred_len, prefixes):
- if is_random_iter:
- data_iter_fn = d2l.data_iter_random
- else:
- data_iter_fn = d2l.data_iter_consecutive
- params = get_params()
- loss = gloss.SoftmaxCrossEntropyLoss()
- for epoch in range(num_epochs):
- if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
- state = init_rnn_state(batch_size, num_hiddens, ctx)
- l_sum, n, start = 0.0, 0, time.time()
- data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, ctx)
- for X, Y in data_iter:
- if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
- state = init_rnn_state(batch_size, num_hiddens, ctx)
- else: # 否则需要使用detach函数从计算图分离隐藏状态
- for s in state:
- s.detach()
- with autograd.record():
- inputs = to_onehot(X, vocab_size)
- # outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
- (outputs, state) = rnn(inputs, state, params)
- # 拼接之后形状为(num_steps * batch_size, vocab_size)
- outputs = nd.concat(*outputs, dim=0)
- # Y的形状是(batch_size, num_steps),转置后再变成长度为
- # batch * num_steps 的向量,这样跟输出的行一一对应
- y = Y.T.reshape((-1,))
- # 使用交叉熵损失计算平均分类误差
- l = loss(outputs, y).mean()
- l.backward()
- grad_clipping(params, clipping_theta, ctx) # 裁剪梯度
- d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
- l_sum += l.asscalar() * y.size
- n += y.size
- if (epoch + 1) % pred_period == 0:
- print('epoch %d, perplexity %f, time %.2f sec' % (
- epoch + 1, math.exp(l_sum / n), time.time() - start))
- for prefix in prefixes:
- print(' -', predict_rnn(
- prefix, pred_len, rnn, params, init_rnn_state,
- num_hiddens, vocab_size, ctx, idx_to_char, char_to_idx))
6.4.8. 训练模型并创作歌词
现在我们可以训练模型了。首先,设置模型超参数。我们将根据前缀“分开”和“不分开”分别创作长度为50个字符(不考虑前缀长度)的一段歌词。我们每过50个迭代周期便根据当前训练的模型创作一段歌词。
- In [12]:
- num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2
- pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
下面采用随机采样训练模型并创作歌词。
- In [13]:
- train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
- vocab_size, ctx, corpus_indices, idx_to_char,
- char_to_idx, True, num_epochs, num_steps, lr,
- clipping_theta, batch_size, pred_period, pred_len,
- prefixes)
- epoch 50, perplexity 66.625915, time 0.24 sec
- - 分开 我不要再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想 我
- - 不分开只 我想要再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想 我不能再想
- epoch 100, perplexity 10.026955, time 0.24 sec
- - 分开 一直用双截 谁截在 旧皮了 什么都有 在人忆 的片段 有一个风霜 老颗 娘殿 征战 弓箭 是箭的回
- - 不分开吗 我爱你的爱写在西元前 深埋在美索不达米亚平原 用十个文字的美土 古底什么前色 学通的客栈人多 牧
- epoch 150, perplexity 2.885564, time 0.24 sec
- - 分开 爱什爱上在在豆瓣酱 我对著黑白照 我后想起你 我不要再难 我不能再想 我不能再想 我不 我不 我不
- - 不分开吗把的胖女巫 用拉丁文念咒语啦啦呜 你已的黑猫笑起来像哭 啦啦啦呜 在谁村 瞎数银囱停 一只灰狼 你
- epoch 200, perplexity 1.597893, time 0.24 sec
- - 分开 有伤心 它给空 我满开任我牵开 从我面著一直日老 就是开不了口让她知道 我一定会呵护著你 也逗你笑
- - 不分开期 我叫你爸 你打我妈 这样对吗 你在操纵 不伤感通 没有梦痛 不伤感动 没有梦 痛不知轻重 也有苦
- epoch 250, perplexity 1.296357, time 0.24 sec
- - 分开球默 想是开不风里三再肉 想要和你融化在一起 融化在宇宙里 我每天每国小的课桌椅 用铅笔写在年的誓言
- - 不分开扫把的胖女巫 用拉丁文念咒语啦啦呜 她养的黑猫笑起来像哭 啦啦啦呜 能谁的练背极红风 还必让酒险鼻子
接下来采用相邻采样训练模型并创作歌词。
- In [14]:
- train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
- vocab_size, ctx, corpus_indices, idx_to_char,
- char_to_idx, False, num_epochs, num_steps, lr,
- clipping_theta, batch_size, pred_period, pred_len,
- prefixes)
- epoch 50, perplexity 63.525007, time 0.24 sec
- - 分开 我想要这 你么我有 你谁了空 我想一直 我想一场 我想一场 我想一场 我想一场 我想一场 我想一场
- - 不分开 别果我 别不我的我 就有一 你有我有 你不了 别不么 我想要这一 我不要再想 我不要再想 我不要
- epoch 100, perplexity 7.411188, time 0.24 sec
- - 分开 一颗我 别怪我 说你怎么 在实一碗热粥 配上的客栈人多 牧草有没有 我马儿有些瘦 景彻入秋 漫天黄
- - 不分开离 你想经离了我 不知不觉 我该好这生活 我知后好 如果我有轻功 飞檐哈兮 快使用双截棍 哼哼哈兮
- epoch 150, perplexity 2.117732, time 0.24 sec
- - 分开 我不要这生活 想不悄悄 是我的外婆家 一起看着日落 一直到我们都睡着 我想就这样牵着你的手不放开
- - 不分开觉 你已经离不离多不知 不道你手不会痛吗 不要我这家打想要知道 我说能会爱护 你想想悄 是脸风外凉过
- epoch 200, perplexity 1.309422, time 0.24 sec
- - 分开 我不要这生活 后静悄悄默都我开攻 我说不黑白力 让我碰著你 这故事 告诉我 印地安的传说 还真是
- - 不分开觉 你在经很了离多妈知透 话说完飞前一只海鸥 大峡谷的风呼啸而过 是谁说没有 有一条热昏头的响尾蛇
- epoch 250, perplexity 1.192337, time 0.24 sec
- - 分开 我不要 是情说著看着 不直为哪 我伤家空我的寂寞 古堡看一片荒步走长b漫 我的世界已狂风暴雨 W
- - 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生
6.4.9. 小结
- 可以用基于字符级循环神经网络的语言模型来生成文本序列,例如创作歌词。
- 当训练循环神经网络时,为了应对梯度爆炸,可以裁剪梯度。
- 困惑度是对交叉熵损失函数做指数运算后得到的值。
6.4.10. 练习
- 调调超参数,观察并分析对运行时间、困惑度以及创作歌词的结果造成的影响。
- 不裁剪梯度,运行本节中的代码,结果会怎样?
- 将
pred_period变量设为1,观察未充分训练的模型(困惑度高)是如何创作歌词的。你获得了什么启发? - 将相邻采样改为不从计算图分离隐藏状态,运行时间有没有变化?
- 将本节中使用的激活函数替换成ReLU,重复本节的实验。
