- A.4 ufunc高级应用
- ufunc实例方法
- 编写新的ufunc
A.4 ufunc高级应用
虽然许多NumPy用户只会用到通用函数所提供的快速的元素级运算,但通用函数实际上还有一些高级用法能使我们丢开循环而编写出更为简洁的代码。
ufunc实例方法
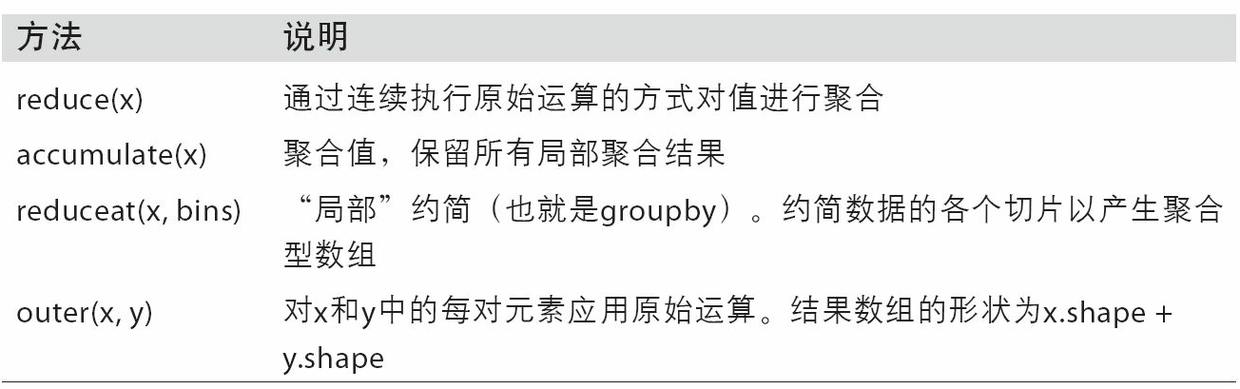
NumPy的各个二元ufunc都有一些用于执行特定矢量化运算的特殊方法。表A-2汇总了这些方法,下面我将通过几个具体的例子对它们进行说明。
reduce接受一个数组参数,并通过一系列的二元运算对其值进行聚合(可指明轴向)。例如,我们可以用np.add.reduce对数组中各个元素进行求和:
In [115]: arr = np.arange(10)In [116]: np.add.reduce(arr)Out[116]: 45In [117]: arr.sum()Out[117]: 45
起始值取决于ufunc(对于add的情况,就是0)。如果设置了轴号,约简运算就会沿该轴向执行。这就使你能用一种比较简洁的方式得到某些问题的答案。在下面这个例子中,我们用np.logical_and检查数组各行中的值是否是有序的:
In [118]: np.random.seed(12346) # for reproducibilityIn [119]: arr = np.random.randn(5, 5)In [120]: arr[::2].sort(1) # sort a few rowsIn [121]: arr[:, :-1] < arr[:, 1:]Out[121]:array([[ True, True, True, True],[False, True, False, False],[ True, True, True, True],[ True, False, True, True],[ True, True, True, True]], dtype=bool)In [122]: np.logical_and.reduce(arr[:, :-1] < arr[:, 1:], axis=1)Out[122]: array([ True, False, True, False, True], dtype=bool)
注意,logical_and.reduce跟all方法是等价的。
ccumulate跟reduce的关系就像cumsum跟sum的关系那样。它产生一个跟原数组大小相同的中间“累计”值数组:
In [123]: arr = np.arange(15).reshape((3, 5))In [124]: np.add.accumulate(arr, axis=1)Out[124]:array([[ 0, 1, 3, 6, 10],[ 5, 11, 18, 26, 35],[10, 21, 33, 46, 60]])
outer用于计算两个数组的叉积:
In [125]: arr = np.arange(3).repeat([1, 2, 2])In [126]: arrOut[126]: array([0, 1, 1, 2, 2])In [127]: np.multiply.outer(arr, np.arange(5))Out[127]:array([[0, 0, 0, 0, 0],[0, 1, 2, 3, 4],[0, 1, 2, 3, 4],[0, 2, 4, 6, 8],[0, 2, 4, 6, 8]])
outer输出结果的维度是两个输入数据的维度之和:
In [128]: x, y = np.random.randn(3, 4), np.random.randn(5)In [129]: result = np.subtract.outer(x, y)In [130]: result.shapeOut[130]: (3, 4, 5)
最后一个方法reduceat用于计算“局部约简”,其实就是一个对数据各切片进行聚合的groupby运算。它接受一组用于指示如何对值进行拆分和聚合的“面元边界”:
In [131]: arr = np.arange(10)In [132]: np.add.reduceat(arr, [0, 5, 8])Out[132]: array([10, 18, 17])
最终结果是在arr[0:5]、arr[5:8]以及arr[8:]上执行的约简。跟其他方法一样,这里也可以传入一个axis参数:
In [133]: arr = np.multiply.outer(np.arange(4), np.arange(5))In [134]: arrOut[134]:array([[ 0, 0, 0, 0, 0],[ 0, 1, 2, 3, 4],[ 0, 2, 4, 6, 8],[ 0, 3, 6, 9, 12]])In [135]: np.add.reduceat(arr, [0, 2, 4], axis=1)Out[135]:array([[ 0, 0, 0],[ 1, 5, 4],[ 2, 10, 8],[ 3, 15, 12]])
表A-2总结了部分的ufunc方法。
编写新的ufunc
有多种方法可以让你编写自己的NumPy ufuncs。最常见的是使用NumPy C API,但它超越了本书的范围。在本节,我们讲纯粹的Python ufunc。
numpy.frompyfunc接受一个Python函数以及两个分别表示输入输出参数数量的参数。例如,下面是一个能够实现元素级加法的简单函数:
In [136]: def add_elements(x, y):.....: return x + yIn [137]: add_them = np.frompyfunc(add_elements, 2, 1)In [138]: add_them(np.arange(8), np.arange(8))Out[138]: array([0, 2, 4, 6, 8, 10, 12, 14], dtype=object)
用frompyfunc创建的函数总是返回Python对象数组,这一点很不方便。幸运的是,还有另一个办法,即numpy.vectorize。虽然没有frompyfunc那么强大,但可以让你指定输出类型:
In [139]: add_them = np.vectorize(add_elements, otypes=[np.float64])In [140]: add_them(np.arange(8), np.arange(8))Out[140]: array([ 0., 2., 4., 6., 8., 10., 12., 14.])
虽然这两个函数提供了一种创建ufunc型函数的手段,但它们非常慢,因为它们在计算每个元素时都要执行一次Python函数调用,这就会比NumPy自带的基于C的ufunc慢很多:
In [141]: arr = np.random.randn(10000)In [142]: %timeit add_them(arr, arr)4.12 ms +- 182 us per loop (mean +- std. dev. of 7 runs, 100 loops each)In [143]: %timeit np.add(arr, arr)6.89 us +- 504 ns per loop (mean +- std. dev. of 7 runs, 100000 loops each)
本章的后面,我会介绍使用Numba(http://numba.pydata.org/),创建快速Python ufuncs。
