- 10.1 GroupBy机制
- 对分组进行迭代
- 选取一列或列的子集
- 通过字典或Series进行分组
- 通过函数进行分组
- 根据索引级别分组
10.1 GroupBy机制
Hadley Wickham(许多热门R语言包的作者)创造了一个用于表示分组运算的术语”split-apply-combine”(拆分-应用-合并)。第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。图10-1大致说明了一个简单的分组聚合过程。
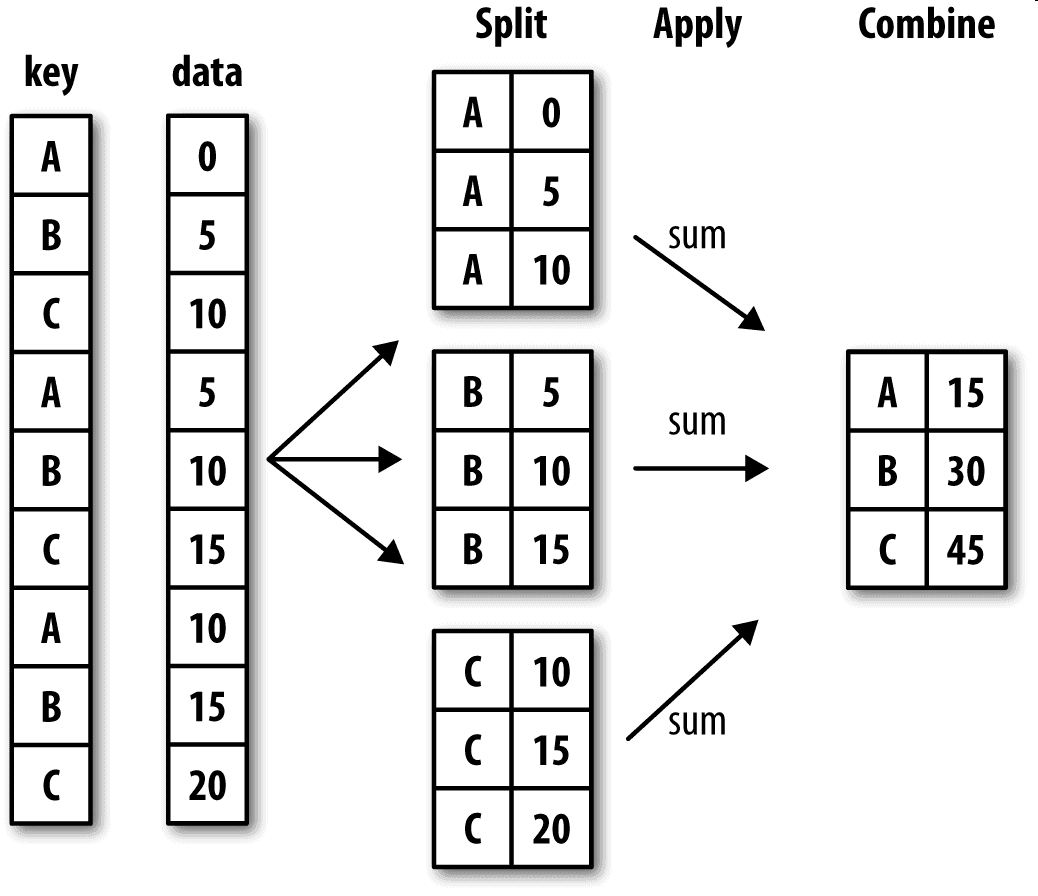
分组键可以有多种形式,且类型不必相同:
- 列表或数组,其长度与待分组的轴一样。
- 表示DataFrame某个列名的值。
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系。
- 函数,用于处理轴索引或索引中的各个标签。
注意,后三种都只是快捷方式而已,其最终目的仍然是产生一组用于拆分对象的值。如果觉得这些东西看起来很抽象,不用担心,我将在本章中给出大量有关于此的示例。首先来看看下面这个非常简单的表格型数据集(以DataFrame的形式):
In [10]: df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],....: 'key2' : ['one', 'two', 'one', 'two', 'one'],....: 'data1' : np.random.randn(5),....: 'data2' : np.random.randn(5)})In [11]: dfOut[11]:data1 data2 key1 key20 -0.204708 1.393406 a one1 0.478943 0.092908 a two2 -0.519439 0.281746 b one3 -0.555730 0.769023 b two4 1.965781 1.246435 a one
假设你想要按key1进行分组,并计算data1列的平均值。实现该功能的方式有很多,而我们这里要用的是:访问data1,并根据key1调用groupby:
In [12]: grouped = df['data1'].groupby(df['key1'])In [13]: groupedOut[13]: <pandas.core.groupby.SeriesGroupBy object at 0x7faa31537390>
变量grouped是一个GroupBy对象。它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已。换句话说,该对象已经有了接下来对各分组执行运算所需的一切信息。例如,我们可以调用GroupBy的mean方法来计算分组平均值:
In [14]: grouped.mean()Out[14]:key1a 0.746672b -0.537585Name: data1, dtype: float64
稍后我将详细讲解.mean()的调用过程。这里最重要的是,数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值。之所以结果中索引的名称为key1,是因为原始DataFrame的列df[‘key1’]就叫这个名字。
如果我们一次传入多个数组的列表,就会得到不同的结果:
In [15]: means = df['data1'].groupby([df['key1'], df['key2']]).mean()In [16]: meansOut[16]:key1 key2a one 0.880536two 0.478943b one -0.519439two -0.555730Name: data1, dtype: float64
这里,我通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成):
In [17]: means.unstack()Out[17]:key2 one twokey1a 0.880536 0.478943b -0.519439 -0.555730
在这个例子中,分组键均为Series。实际上,分组键可以是任何长度适当的数组:
In [18]: states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])In [19]: years = np.array([2005, 2005, 2006, 2005, 2006])In [20]: df['data1'].groupby([states, years]).mean()Out[20]:California 2005 0.4789432006 -0.519439Ohio 2005 -0.3802192006 1.965781Name: data1, dtype: float64
通常,分组信息就位于相同的要处理DataFrame中。这里,你还可以将列名(可以是字符串、数字或其他Python对象)用作分组键:
In [21]: df.groupby('key1').mean()Out[21]:data1 data2key1a 0.746672 0.910916b -0.537585 0.525384In [22]: df.groupby(['key1', 'key2']).mean()Out[22]:data1 data2key1 key2a one 0.880536 1.319920two 0.478943 0.092908b one -0.519439 0.281746two -0.555730 0.769023
你可能已经注意到了,第一个例子在执行df.groupby(‘key1’).mean()时,结果中没有key2列。这是因为df[‘key2’]不是数值数据(俗称“麻烦列”),所以被从结果中排除了。默认情况下,所有数值列都会被聚合,虽然有时可能会被过滤为一个子集,稍后就会碰到。
无论你准备拿groupby做什么,都有可能会用到GroupBy的size方法,它可以返回一个含有分组大小的Series:
In [23]: df.groupby(['key1', 'key2']).size()Out[23]:key1 key2a one 2two 1b one 1two 1dtype: int64
注意,任何分组关键词中的缺失值,都会被从结果中除去。
对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。看下面的例子:
In [24]: for name, group in df.groupby('key1'):....: print(name)....: print(group)....:adata1 data2 key1 key20 -0.204708 1.393406 a one1 0.478943 0.092908 a two4 1.965781 1.246435 a onebdata1 data2 key1 key22 -0.519439 0.281746 b one3 -0.555730 0.769023 b two
对于多重键的情况,元组的第一个元素将会是由键值组成的元组:
In [25]: for (k1, k2), group in df.groupby(['key1', 'key2']):....: print((k1, k2))....: print(group)....:('a', 'one')data1 data2 key1 key20 -0.204708 1.393406 a one4 1.965781 1.246435 a one('a', 'two')data1 data2 key1 key21 0.478943 0.092908 a two('b', 'one')data1 data2 key1 key22 -0.519439 0.281746 b one('b', 'two')data1 data2 key1 key23 -0.55573 0.769023 b two
当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算:将这些数据片段做成一个字典:
In [26]: pieces = dict(list(df.groupby('key1')))In [27]: pieces['b']Out[27]:data1 data2 key1 key22 -0.519439 0.281746 b one3 -0.555730 0.769023 b two
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。拿上面例子中的df来说,我们可以根据dtype对列进行分组:
In [28]: df.dtypesOut[28]:data1 float64data2 float64key1 objectkey2 objectdtype: objectIn [29]: grouped = df.groupby(df.dtypes, axis=1)
可以如下打印分组:
In [30]: for dtype, group in grouped:....: print(dtype)....: print(group)....:float64data1 data20 -0.204708 1.3934061 0.478943 0.0929082 -0.519439 0.2817463 -0.555730 0.7690234 1.965781 1.246435objectkey1 key20 a one1 a two2 b one3 b two4 a one
选取一列或列的子集
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的。也就是说:
df.groupby('key1')['data1']df.groupby('key1')[['data2']]
是以下代码的语法糖:
df['data1'].groupby(df['key1'])df[['data2']].groupby(df['key1'])
尤其对于大数据集,很可能只需要对部分列进行聚合。例如,在前面那个数据集中,如果只需计算data2列的平均值并以DataFrame形式得到结果,可以这样写:
In [31]: df.groupby(['key1', 'key2'])[['data2']].mean()Out[31]:data2key1 key2a one 1.319920two 0.092908b one 0.281746two 0.769023
这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列名):
In [32]: s_grouped = df.groupby(['key1', 'key2'])['data2']In [33]: s_groupedOut[33]: <pandas.core.groupby.SeriesGroupBy object at 0x7faa30c78da0>In [34]: s_grouped.mean()Out[34]:key1 key2a one 1.319920two 0.092908b one 0.281746two 0.769023Name: data2, dtype: float64
通过字典或Series进行分组
除数组以外,分组信息还可以其他形式存在。来看另一个示例DataFrame:
In [35]: people = pd.DataFrame(np.random.randn(5, 5),....: columns=['a', 'b', 'c', 'd', 'e'],....: index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])In [36]: people.iloc[2:3, [1, 2]] = np.nan # Add a few NA valuesIn [37]: peopleOut[37]:a b c d eJoe 1.007189 -1.296221 0.274992 0.228913 1.352917Steve 0.886429 -2.001637 -0.371843 1.669025 -0.438570Wes -0.539741 NaN NaN -1.021228 -0.577087Jim 0.124121 0.302614 0.523772 0.000940 1.343810Travis -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
现在,假设已知列的分组关系,并希望根据分组计算列的和:
In [38]: mapping = {'a': 'red', 'b': 'red', 'c': 'blue',....: 'd': 'blue', 'e': 'red', 'f' : 'orange'}
现在,你可以将这个字典传给groupby,来构造数组,但我们可以直接传递字典(我包含了键“f”来强调,存在未使用的分组键是可以的):
In [39]: by_column = people.groupby(mapping, axis=1)In [40]: by_column.sum()Out[40]:blue redJoe 0.503905 1.063885Steve 1.297183 -1.553778Wes -1.021228 -1.116829Jim 0.524712 1.770545Travis -4.230992 -2.405455
Series也有同样的功能,它可以被看做一个固定大小的映射:
In [41]: map_series = pd.Series(mapping)In [42]: map_seriesOut[42]:a redb redc blued bluee redf orangedtype: objectIn [43]: people.groupby(map_series, axis=1).count()Out[43]:blue redJoe 2 3Steve 2 3Wes 1 2Jim 2 3Travis 2 3
通过函数进行分组
比起使用字典或Series,使用Python函数是一种更原生的方法定义分组映射。任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。具体点说,以上一小节的示例DataFrame为例,其索引值为人的名字。你可以计算一个字符串长度的数组,更简单的方法是传入len函数:
In [44]: people.groupby(len).sum()Out[44]:a b c d e3 0.591569 -0.993608 0.798764 -0.791374 2.1196395 0.886429 -2.001637 -0.371843 1.669025 -0.4385706 -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
将函数跟数组、列表、字典、Series混合使用也不是问题,因为任何东西在内部都会被转换为数组:
In [45]: key_list = ['one', 'one', 'one', 'two', 'two']In [46]: people.groupby([len, key_list]).min()Out[46]:a b c d e3 one -0.539741 -1.296221 0.274992 -1.021228 -0.577087two 0.124121 0.302614 0.523772 0.000940 1.3438105 one 0.886429 -2.001637 -0.371843 1.669025 -0.4385706 two -0.713544 -0.831154 -2.370232 -1.860761 -0.860757
根据索引级别分组
层次化索引数据集最方便的地方就在于它能够根据轴索引的一个级别进行聚合:
In [47]: columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],....: [1, 3, 5, 1, 3]],....: names=['cty', 'tenor'])In [48]: hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)In [49]: hier_dfOut[49]:cty US JPtenor 1 3 5 1 30 0.560145 -1.265934 0.119827 -1.063512 0.3328831 -2.359419 -0.199543 -1.541996 -0.970736 -1.3070302 0.286350 0.377984 -0.753887 0.331286 1.3497423 0.069877 0.246674 -0.011862 1.004812 1.327195
要根据级别分组,使用level关键字传递级别序号或名字:
In [50]: hier_df.groupby(level='cty', axis=1).count()Out[50]:cty JP US0 2 31 2 32 2 33 2 3
